/
Blog · BaseTech
Toate articolele
Insights despre ERP, AI/RAG, agenți autonomi, pSEO, SaaS și data pipelines — scrise pentru companii care construiesc.
Insights despre ERP, AI/RAG, agenți autonomi, pSEO, SaaS și data pipelines — scrise pentru companii care construiesc.
RAG conectează un model AI la documentele tale înainte să răspundă. Înțelegi cum funcționează, când îl folosești și ce stack tehnic ai nevoie pentru un MVP funcțional în 2-4 săptămâni.

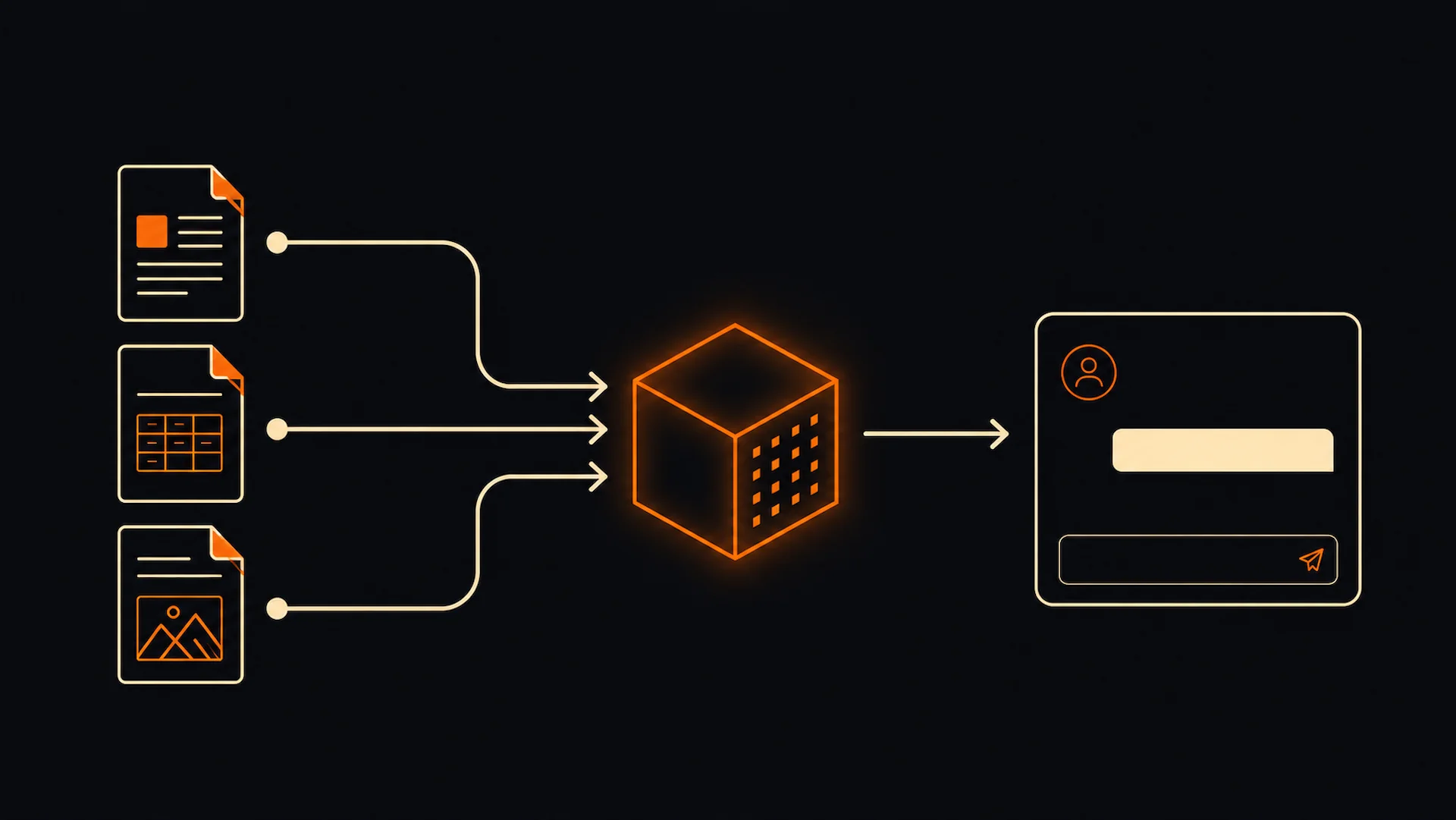
Ai un LLM. Îl întrebi ceva despre contractul semnat luna trecută. Habar n-are.
Asta e problema pe care o rezolvă RAG.
RAG (Retrieval-Augmented Generation) este o arhitectură AI care conectează un model de limbaj la o bază de date proprie înainte să genereze un răspuns.
În loc să răspundă din memorie antrenată, modelul caută mai întâi contextul relevant din documentele tale, apoi construiește răspunsul pe baza lui.
Rezultat: răspunsuri pe datele tale, cu citare la sursă, fără halucinații inventate.

Trei pași. Fiecare are un rol clar.
Iei documentele — PDF-uri, pagini Notion, contracte, tickete Zendesk, orice text structurat. Le împarți în bucăți (chunks) de 200-500 tokens.
Fiecare bucată e transformată într-un vector numeric prin embeddings (OpenAI, Cohere, sau modele open-source). Vectorii sunt stocați într-o bază vectorială: Pinecone, Qdrant, pgvector.
De acum, fiecare document e „căutabil" semantic — nu doar după cuvinte cheie, ci după înțeles.
Utilizatorul pune o întrebare. Întrebarea e transformată în același spațiu vectorial. Sistemul calculează similaritatea între vectorul întrebării și toți vectorii din bază. Returnează top 3-10 chunk-uri cele mai relevante.
Acesta e retrieval-ul. Nu caută după keyword — înțelege semantic că „reziliere contract" și „clauza de terminare" sunt același lucru.
Chunk-urile găsite sunt injectate în promptul trimis LLM-ului (GPT-4o, Claude, Mistral etc.) împreună cu întrebarea originală. Modelul generează răspunsul strict bazat pe contextul primit, nu din memoria antrenată.
Dacă adaugi citare la sursă în prompt, modelul indică exact din ce document a extras informația.

| LLM fără RAG | LLM cu RAG | |
|---|---|---|
| Cunoaștere | Date de antrenament (cutoff fix) | Documentele tale, actualizate |
| Acuratețe pe date proprii | Slabă, halucinează | Ridicată, cu citare |
| Actualizare | Reantrenare costisitoare | Adaugi documente noi în bază |
| Trasabilitate | Zero | Știi exact din ce a răspuns |
| Cost | API per token | API + infra vector DB |
Cel mai important câștig: trasabilitate. Într-un context enterprise, nu poți livra un chatbot care inventează politici HR sau clauze contractuale.
RAG rezolvă asta structural.
Asta e întrebarea care apare garantat în orice evaluare.
Fine-tuning = reantrenezi modelul pe datele tale. Modelul „memorează" stilul, terminologia, structura. Util când vrei un model care scrie ca tine sau înțelege jargonul intern. Nu e util când datele se schimbă des sau când ai nevoie de răspunsuri trasabile la sursă.
RAG = nu modifici modelul, îi dai context la runtime. Util când:
datele se actualizează frecvent (politici, contracte, documentație)
ai nevoie de citare exactă
vrei control granular pe ce informații accesează modelul
nu ai buget de fine-tuning (zeci de mii de $ pentru modele mari)
În practică: RAG câștigă în 80% din cazurile enterprise.
Fine-tuning e complementar, nu alternativă.
Citește ghidul complet RAG vs. fine-tuning.
Ai documentație internă pe care angajații o caută manual zilnic
Suportul tău răspunde la aceleași 50 de întrebări din 3 surse diferite
Ai contracte, politici sau proceduri care se actualizează trimestrial
Vrei un chatbot care să citeze exact, nu să improvizeze
Datele sunt sensibile și nu pot ieși din infrastructura ta
Dacă bifezi 2+ din lista de mai sus, RAG e justificat tehnic și economic.
Ai sub 50 de documente scurte — un search clasic e suficient
Vrei creativitate, nu acuratețe factuală — un LLM simplu e mai bun
Întrebările nu necesită context specific companiei tale
Nu ai proces de actualizare a documentelor — baza RAG stagnează și devine
la fel de inutilă ca un wiki abandonat
Customer support: companie SaaS cu 3000 de tichete/lună.
60% din tichete = întrebări acoperite în documentația produsului.
Un sistem RAG pe documentație + changelog reduce volumul cu 35-45%.
Agenții rămân pentru cazuri complexe.
Vezi cum construim RAG pentru customer support.
HR intern: politicile de concediu, procedurile de onboarding, beneficiile — toate răspândite în 12 documente Word. Un chatbot RAG pe Slack elimină 20 de întrebări/zi către HR.
Sales enablement: echipa de vânzări întreabă despre specificații tehnice în mijlocul unui demo. Un asistent RAG pe documentația tehnică + deck-uri returnează răspunsul în 3 secunde, cu citare la slide.
Nu ai nevoie de un cluster Kubernetes pentru prima versiune.
Document ingestion → LangChain / LlamaIndex Embeddings → OpenAI text-embedding-3-small (cost redus) sau nomic-embed-text (open-source) Vector store → pgvector (dacă ai deja Postgres) sau Qdrant self-hosted LLM → GPT-4o / Claude 3.5 Sonnet / Mistral API layer → Next.js API routes + Vercel AI SDK (streaming) Un MVP funcțional pe documentație internă: 2-4 săptămâni de development, cost infra sub 100$/lună la volum moderat.
Vezi breakdown-ul complet de costuri sistem RAG.
RAG (Retrieval-Augmented Generation) e o metodă prin care un model AI caută informații din documente proprii înainte să genereze un răspuns.
Rezultatul e un asistent care răspunde pe datele tale, nu din memoria antrenată.
Da. Modelele de embeddings moderne (OpenAI, Cohere, nomic) suportă multilingv inclusiv română. Calitatea semantic search-ului e comparabilă cu engleza pentru texte tehnice.
Un MVP pe 100-500 documente: 2-4 săptămâni cu un developer experimentat.
Un sistem productionizat cu evaluare, monitoring și actualizare automată: 6-10 săptămâni.
Depinde de arhitectura aleasă. Dacă folosești OpenAI API, documentele trec prin serverele lor (cu protecție conform contractului enterprise).
Pentru date sensibile (medicale, juridice, financiare), există opțiunea self-hosted cu Ollama + modele open-source — documentele nu ies din infrastructura ta.
Nu înlocuiește, complementează. Motorul de căutare clasic (BM25/Elasticsearch) e mai bun pe keyword exact. RAG e mai bun pe înțeles semantic și răspunsuri conversaționale. Sistemele hibride combină ambele și obțin cel mai bun rezultat.
Retrieval-ul merge cu orice model de embeddings. Generation-ul merge și cu modele mai mici (Mistral 7B, Llama 3) dacă contextul e clar și instrucțiunile sunt precise. GPT-4o e recomandat pentru cazuri unde răspunsul necesită raționament complex pe mai multe surse.
RAG nu e magie. E o arhitectură cu trei componente clare — ingestion, retrieval, generation — care rezolvă o problemă reală: modelele AI nu știu ce știi tu.
Dacă ai documentație internă care stă neutilizată sau o echipă de suport care răspunde la aceleași întrebări zilnic, RAG e investiția cu cel mai rapid ROI din stack-ul AI actual.
Construim sisteme RAG pe stack Next.js + Vercel AI SDK + vector DB ales în funcție de datele tale. Vorbim despre cazul tău concret →

Compari RAG cu fine-tuning pe 8 criterii. Vezi 3 scenarii cu cost real și decision tree în 4 întrebări pentru a alege arhitectura corectă.
Articole noi despre ERP, AI, agenți și pSEO, direct pe email. Fără spam.