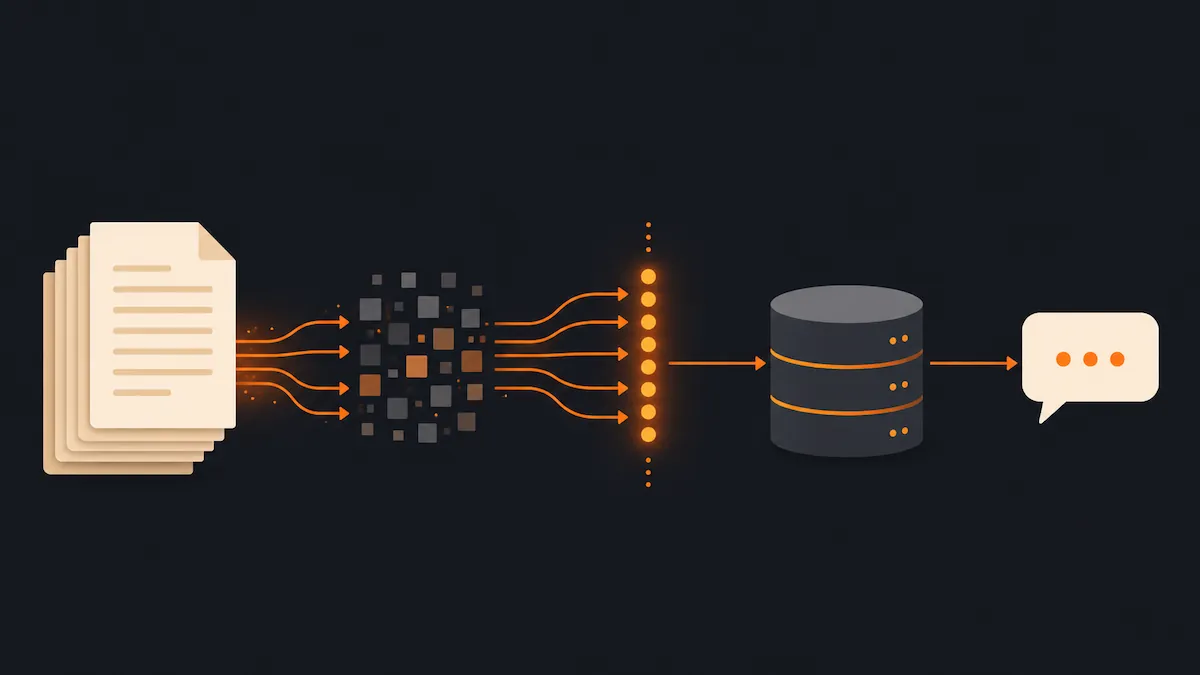
Un model lingvistic nu știe nimic despre documentele tale interne. RAG (Retrieval-Augmented Generation) rezolvă asta: cauți bucățile relevante din baza ta de cunoștințe, le pui în context și lași modelul să răspundă pe baza lor.
Multe ghiduri adaugă o bază de date vectorială separată — Pinecone, Qdrant sau pgvector. Nu e obligatoriu. Dacă folosești deja MongoDB, Atlas Vector Search ține embeddings în aceeași colecție cu datele tale: mai puțină infrastructură, un singur loc de administrat. Tot stack-ul: Next.js 16, Vercel AI SDK și MongoDB. Cod complet, pas cu pas.
Dacă nu ești sigur ce e RAG sau dacă e alegerea potrivită, citește mai întâi ce este RAG și când îl folosești.
Sistemul are două fluxuri.
Ingestion (o dată, sau când adaugi documente):
- Spargi documentul în bucăți mici (chunks).
- Generezi un embedding pentru fiecare bucată.
- Stochezi bucata + vectorul în MongoDB.
Query (la fiecare întrebare):
- Generezi un embedding pentru întrebare.
- Cauți semantic în Mongo cu
$vectorSearch.
- Pui bucățile găsite în system prompt și apelezi
streamText.
Atât. Restul e cod.

- MongoDB Atlas — vector search rulează doar pe Atlas (clusterul M0 gratuit merge pentru test), nu pe un MongoDB community obișnuit.
- Cheie OpenAI — pentru embeddings și generare.
- Pachetele AI SDK:
1npm install ai @ai-sdk/openai @ai-sdk/react
1npm install ai @ai-sdk/openai @ai-sdk/react
Mongoose îl ai deja în proiect. Folosim modelul text-embedding-3-small (1536 dimensiuni) — ieftin și suficient pentru majoritatea cazurilor.
Întâi, un model pentru bucăți. Câmpul embedding e un array de numere.
1// database/embedding.model.ts
2import { model, models, Schema } from "mongoose";
3
4export interface IEmbedding {
5 source: string; // ce document a generat această bucată
6 content: string; // textul bucății
7 embedding: number[]; // 1536 numere de la text-embedding-3-small
8}
9
10const EmbeddingSchema = new Schema<IEmbedding>(
11 {
12 source: { type: String, required: true, index: true },
13 content: { type: String, required: true },
14 embedding: { type: [Number], required: true },
15 },
16 { timestamps: true },
17);
18
19const Embedding =
20 models?.Embedding || model<IEmbedding>("Embedding", EmbeddingSchema);
21
22export default Embedding;
1// database/embedding.model.ts
2import { model, models, Schema } from "mongoose";
3
4export interface IEmbedding {
5 source: string; // ce document a generat această bucată
6 content: string; // textul bucății
7 embedding: number[]; // 1536 numere de la text-embedding-3-small
8}
9
10const EmbeddingSchema = new Schema<IEmbedding>(
11 {
12 source: { type: String, required: true, index: true },
13 content: { type: String, required: true },
14 embedding: { type: [Number], required: true },
15 },
16 { timestamps: true },
17);
18
19const Embedding =
20 models?.Embedding || model<IEmbedding>("Embedding", EmbeddingSchema);
21
22export default Embedding;
Apoi, indexul vectorial. Atenție: acesta nu se creează din Mongoose. Îl definești în Atlas (UI → Atlas Search → Create Index, tip vectorSearch), cu acest JSON:
1{
2 "fields": [
3 {
4 "type": "vector",
5 "path": "embedding",
6 "numDimensions": 1536,
7 "similarity": "cosine"
8 },
9 {
10 "type": "filter",
11 "path": "source"
12 }
13 ]
14}
1{
2 "fields": [
3 {
4 "type": "vector",
5 "path": "embedding",
6 "numDimensions": 1536,
7 "similarity": "cosine"
8 },
9 {
10 "type": "filter",
11 "path": "source"
12 }
13 ]
14}
numDimensions trebuie să fie exact 1536. Dacă schimbi modelul de embedding, schimbi și numărul aici — altfel indexul respinge vectorii. Câmpul filter pe source îți permite mai târziu să cauți doar într-un anumit document.
Modelul de embedding pierde calitate pe texte lungi. Deci spargi documentul în bucăți. O variantă simplă, cu overlap ca să nu tai ideile la mijloc:
1// lib/rag/chunk.ts
2export function chunkText(text: string, size = 800, overlap = 100): string[] {
3 const clean = text.replace(/s+/g, " ").trim();
4 const chunks: string[] = [];
5 for (let i = 0; i < clean.length; i += size - overlap) {
6 chunks.push(clean.slice(i, i + size));
7 }
8 return chunks;
9}
1// lib/rag/chunk.ts
2export function chunkText(text: string, size = 800, overlap = 100): string[] {
3 const clean = text.replace(/s+/g, " ").trim();
4 const chunks: string[] = [];
5 for (let i = 0; i < clean.length; i += size - overlap) {
6 chunks.push(clean.slice(i, i + size));
7 }
8 return chunks;
9}
Pentru producție, un chunking pe paragrafe sau propoziții dă rezultate mai bune. Pentru un MVP, varianta de mai sus e suficientă.
Acum generezi embeddings pentru toate bucățile dintr-un singur apel cu embedMany și le salvezi:
1// lib/rag/ingest.ts
2import { openai } from "@ai-sdk/openai";
3import { embedMany } from "ai";
4import dbConnect from "@/lib/mongoose";
5import Embedding from "@/database/embedding.model";
6import { chunkText } from "./chunk";
7
8export async function ingestDocument(source: string, raw: string) {
9 await dbConnect();
10
11 const chunks = chunkText(raw);
12
13 const { embeddings } = await embedMany({
14 model: openai.embedding("text-embedding-3-small"),
15 values: chunks,
16 });
17
18 await Embedding.insertMany(
19 chunks.map((content, i) => ({
20 source,
21 content,
22 embedding: embeddings[i],
23 })),
24 );
25
26 return chunks.length;
27}
1// lib/rag/ingest.ts
2import { openai } from "@ai-sdk/openai";
3import { embedMany } from "ai";
4import dbConnect from "@/lib/mongoose";
5import Embedding from "@/database/embedding.model";
6import { chunkText } from "./chunk";
7
8export async function ingestDocument(source: string, raw: string) {
9 await dbConnect();
10
11 const chunks = chunkText(raw);
12
13 const { embeddings } = await embedMany({
14 model: openai.embedding("text-embedding-3-small"),
15 values: chunks,
16 });
17
18 await Embedding.insertMany(
19 chunks.map((content, i) => ({
20 source,
21 content,
22 embedding: embeddings[i],
23 })),
24 );
25
26 return chunks.length;
27}
embedMany trimite toate bucățile odată și păstrează ordinea — embeddings[i] corespunde lui chunks[i].
La query, generezi embedding pentru întrebare cu embed, apoi rulezi un pipeline de agregare. $vectorSearch trebuie să fie prima etapă:
1// lib/rag/retrieve.ts
2import { openai } from "@ai-sdk/openai";
3import { embed } from "ai";
4import dbConnect from "@/lib/mongoose";
5import Embedding from "@/database/embedding.model";
6
7export async function retrieve(query: string, k = 5) {
8 await dbConnect();
9
10 const { embedding } = await embed({
11 model: openai.embedding("text-embedding-3-small"),
12 value: query,
13 });
14
15 return Embedding.aggregate([
16 {
17 $vectorSearch: {
18 index: "embeddings_vector_index",
19 path: "embedding",
20 queryVector: embedding,
21 numCandidates: 100,
22 limit: k,
23 },
24 },
25 {
26 $project: {
27 _id: 0,
28 content: 1,
29 source: 1,
30 score: { $meta: "vectorSearchScore" },
31 },
32 },
33 { $match: { score: { $gte: 0.5 } } },
34 ]);
35}
1// lib/rag/retrieve.ts
2import { openai } from "@ai-sdk/openai";
3import { embed } from "ai";
4import dbConnect from "@/lib/mongoose";
5import Embedding from "@/database/embedding.model";
6
7export async function retrieve(query: string, k = 5) {
8 await dbConnect();
9
10 const { embedding } = await embed({
11 model: openai.embedding("text-embedding-3-small"),
12 value: query,
13 });
14
15 return Embedding.aggregate([
16 {
17 $vectorSearch: {
18 index: "embeddings_vector_index",
19 path: "embedding",
20 queryVector: embedding,
21 numCandidates: 100,
22 limit: k,
23 },
24 },
25 {
26 $project: {
27 _id: 0,
28 content: 1,
29 source: 1,
30 score: { $meta: "vectorSearchScore" },
31 },
32 },
33 { $match: { score: { $gte: 0.5 } } },
34 ]);
35}
Câteva detalii care contează:
index e numele exact al indexului din Atlas. Greșești numele → zero rezultate, fără eroare.numCandidates (câți vectori scanează) trebuie să fie mai mare decât limit. 100 e un punct bun de plecare.vectorSearchScore merge de la 0 la 1. Filtrul $gte: 0.5 aruncă bucățile slabe, ca să nu bagi zgomot în context.

Endpoint-ul de chat. Extragi întrebarea, faci retrieval, pui contextul în system prompt și dai drumul la streaming:
1// app/api/chat/route.ts
2import { openai } from "@ai-sdk/openai";
3import { streamText, convertToModelMessages, type UIMessage } from "ai";
4import { retrieve } from "@/lib/rag/retrieve";
5
6export async function POST(req: Request) {
7 const { messages }: { messages: UIMessage[] } = await req.json();
8
9 const last = messages[messages.length - 1];
10 const query = last.parts
11 .filter((p) => p.type === "text")
12 .map((p) => p.text)
13 .join(" ");
14
15 const context = await retrieve(query);
16 const contextText = context.map((c) => c.content).join("n---n");
17
18 const result = streamText({
19 model: openai("gpt-4o"),
20 system: `Răspunzi strict pe baza contextului de mai jos. Dacă informația nu există în context, spui clar că nu o ai. Nu inventezi.
21
22Context:
23${contextText}`,
24 messages: convertToModelMessages(messages),
25 });
26
27 return result.toUIMessageStreamResponse();
28}
1// app/api/chat/route.ts
2import { openai } from "@ai-sdk/openai";
3import { streamText, convertToModelMessages, type UIMessage } from "ai";
4import { retrieve } from "@/lib/rag/retrieve";
5
6export async function POST(req: Request) {
7 const { messages }: { messages: UIMessage[] } = await req.json();
8
9 const last = messages[messages.length - 1];
10 const query = last.parts
11 .filter((p) => p.type === "text")
12 .map((p) => p.text)
13 .join(" ");
14
15 const context = await retrieve(query);
16 const contextText = context.map((c) => c.content).join("n---n");
17
18 const result = streamText({
19 model: openai("gpt-4o"),
20 system: `Răspunzi strict pe baza contextului de mai jos. Dacă informația nu există în context, spui clar că nu o ai. Nu inventezi.
21
22Context:
23${contextText}`,
24 messages: convertToModelMessages(messages),
25 });
26
27 return result.toUIMessageStreamResponse();
28}
Două lucruri specifice AI SDK 5:
convertToModelMessages transformă mesajele din format UI (cele de la useChat) în formatul pe care îl așteaptă modelul.- Răspunsul se întoarce cu
toUIMessageStreamResponse(). Dacă ai văzut toDataStreamResponse() în tutoriale vechi — a dispărut în v5.
System prompt-ul care îi spune modelului să nu inventeze e partea cea mai importantă. Fără el, modelul completează golurile din memoria lui și pierzi tot rostul RAG-ului.
Componenta de client. În AI SDK 5, useChat vine din @ai-sdk/react, gestionezi tu input-ul, iar mesajele sunt array de parts:
1// app/chat/page.tsx
2"use client";
3
4import { useChat } from "@ai-sdk/react";
5import { useState } from "react";
6
7export default function Chat() {
8 const [input, setInput] = useState("");
9 const { messages, sendMessage, status } = useChat();
10
11 return (
12 <div className="mx-auto flex max-w-2xl flex-col gap-4 p-4">
13 {messages.map((m) => (
14 <div key={m.id}>
15 <strong>{m.role === "user" ? "Tu" : "Asistent"}: </strong>
16 {m.parts.map((part, i) =>
17 part.type === "text" ? <span key={i}>{part.text}</span> : null,
18 )}
19 </div>
20 ))}
21
22 <input
23 value={input}
24 onChange={(e) => setInput(e.target.value)}
25 onKeyDown={(e) => {
26 if (e.key === "Enter" && input.trim()) {
27 sendMessage({ text: input });
28 setInput("");
29 }
30 }}
31 placeholder="Întreabă ceva despre documentele tale..."
32 className="rounded-full border px-4 py-2"
33 />
34 {status === "streaming" && <p>Se generează răspunsul...</p>}
35 </div>
36 );
37}
1// app/chat/page.tsx
2"use client";
3
4import { useChat } from "@ai-sdk/react";
5import { useState } from "react";
6
7export default function Chat() {
8 const [input, setInput] = useState("");
9 const { messages, sendMessage, status } = useChat();
10
11 return (
12 <div className="mx-auto flex max-w-2xl flex-col gap-4 p-4">
13 {messages.map((m) => (
14 <div key={m.id}>
15 <strong>{m.role === "user" ? "Tu" : "Asistent"}: </strong>
16 {m.parts.map((part, i) =>
17 part.type === "text" ? <span key={i}>{part.text}</span> : null,
18 )}
19 </div>
20 ))}
21
22 <input
23 value={input}
24 onChange={(e) => setInput(e.target.value)}
25 onKeyDown={(e) => {
26 if (e.key === "Enter" && input.trim()) {
27 sendMessage({ text: input });
28 setInput("");
29 }
30 }}
31 placeholder="Întreabă ceva despre documentele tale..."
32 className="rounded-full border px-4 py-2"
33 />
34 {status === "streaming" && <p>Se generează răspunsul...</p>}
35 </div>
36 );
37}
sendMessage({ text: input }) trimite întrebarea către /api/chat. Răspunsul curge înapoi token cu token. Gata — ai un sistem RAG funcțional.
MVP-ul de mai sus merge. Înainte să-l pui în fața clienților, ai grijă la:
- Indexul nu e gata instant. După ce-l creezi în Atlas, durează câteva secunde până se construiește. Până atunci,
$vectorSearch întoarce zero rezultate. Verifică statusul în Atlas.
- Nepotrivirea de dimensiuni.
text-embedding-3-small are 1536, text-embedding-3-large are 3072. Dacă schimbi modelul fără să refaci indexul și să re-embeddezi tot, totul se rupe în tăcere.
- Costul la ingestion. Re-embeddarea unei baze mari de documente costă. Salvează vectorii o dată; nu-i regenera la fiecare deployment.
- Mărimea chunk-ului. Bucăți prea mari diluează relevanța, prea mici pierd contextul. 500–1000 de caractere e un interval rezonabil de la care pornești și măsori.
- Filtrarea pe sursă. Câmpul
filter din index îți permite să restrângi căutarea la un singur document sau client. Esențial pentru aplicații multi-tenant.
- Evaluarea. Fără un set de întrebări de test, nu știi dacă o schimbare a îmbunătățit sau a stricat retrieval-ul. Măsoară, nu ghici.
Pentru când abordarea asta nu e suficientă, compară cu alternativa în RAG vs fine-tuning. Și dacă vrei tot ecosistemul de implementare, ai mai multe articole în categoria Implementare & Stack Tehnic.
Nu pentru $vectorSearch. Vector search e o funcție Atlas. Poți rula un deployment Atlas local prin Atlas CLI pentru dezvoltare, dar nu merge pe un MongoDB community obișnuit.
text-embedding-3-small (1536 dimensiuni) e ieftin și bun pentru majoritatea cazurilor. Treci la text-embedding-3-large doar dacă măsori o nevoie reală de acuratețe mai mare — și nu uita să schimbi numDimensions în index.
Începe cu 5. Prea puține și modelul n-are context; prea multe și umpli fereastra de context cu zgomot și plătești mai mulți tokeni. Ajustează în funcție de mărimea chunk-urilor.
Trei cauze frecvente: numele indexului e greșit, indexul încă se construiește, sau numDimensions nu se potrivește cu vectorii salvați. Verifică-le în ordinea asta.
Da. Vercel AI SDK e agnostic de provider. Schimbi openai(...) cu anthropic(...) sau alt adapter pentru generare. Pentru embeddings, asigură-te că numDimensions din index se potrivește cu modelul ales.
Depinde de volumul de documente și de trafic. Costurile principale sunt embeddings (o dată, la ingestion) și apelurile de generare (la fiecare întrebare). Detaliem bugetul într-un articol dedicat: cât costă un sistem RAG.
Ai acum un sistem RAG complet pe stack-ul tău, fără infrastructură vectorială separată. Construim astfel de sisteme end-to-end — cu evaluare, filtrare pe surse și deployment în producție — ca parte din serviciul de Integrări AI & RAG. Hai să vorbim despre proiectul tău.